


An automated grape yield estimation system
Baden Parr & Dr Mathew Legg – Massey University, Auckland
Accurate and timely vineyard yield estimation can have a significant effect on the profitability of vineyards. Amongst other reasons, this can be due to better management of vineyard logistics, precise application of vine in-puts, and the delineation of grape quality at harvest to optimise returns. Traditionally, the process of yield estimation is conducted manually leading to subjective estimations. Furthermore, the financial burden of manual sampling often results in under sampled vineyards resulting in ineffective vineyard management. To this end, automating yield estimation is the focus of ongoing research in the computer vision field.
Current 2D camera techniques predominantly rely on distinct features of grapes, such as colour or texture, in order to identify and count them within sequences of images. This approach has been reported to correctly identify over 90% of the visible grapes within each image. However, the accuracy of yield estimations from these approaches is greatly restricted by the number of grapes visible to the cameras. It is common for grape clusters to be at least partially occluded by leaves and branches.
Traditional laser scanners have shown promising results for accurate phenotype of grape clusters. However, accurate sensors are costly, required a significant time to capture viable point-clouds, and their use has yet to be demonstrated within field environments. In recent years, low-cost 3D cameras, that operate in real-time, have been introduced to the market. To date, there has been little investigation into the use of these cameras for yield estimation in vineyards.
Commercially available 3D cameras, utilising structured light technology, have demonstrated promising early results within vineyards. The Microsoft Kinect V1 has seen use for the volumetric assessment of vine canopies as well as analysing vine structure for the purpose of automated pruning. However, to date, there has been little direct research into their use for this purpose.
There is a need for an investigation into the performance characteristics of 3D cameras as they directly relate the acquisition of information for grape yield estimation. Vineyard rows are typically only a few meters wide and any 3D capture equipment can expect to be between 0.5m – 1.0m from a vine at any given time. The resolution and accuracy of the scan at this range must be enough so that individual grapes are identifiable. Additionally, as grapes are approximately spherical and grow in dense clusters, there are concerns that convex regions between neighbouring grapes may become blurred, due in part to the loss of accuracy at increasing angles of incidence and the low spatial resolution of the sensors. In this case, algorithms that rely on the identification of spherical structures for the identification of grapes within point-clouds, may face increased difficulties. To work within the constraints of these 3D cameras, a new algorithm is underdevelopment with the goal of providing robust real-time identification of individual grapes within a captured point-cloud.
Grape Identification Algorithm
Once a 3D camera has captured a scan of a grape cluster, it is then necessary to analyse the resulting point cloud to identify the individual grapes. The algorithm currently in development has been designed to work within the constraints of 3D cameras and provide accurate estimations of where grapes are, their size, and a degree of confidence about the estimate.
The algorithm works on the assumption that the surface of a grape visible is approximately spherical. Therefore, by finding spheres within a point-cloud we should also be able to identify grapes. Unfortunately, finding spheres in 3D camera scans of grape clusters is not trivial. Grape clusters are complex structures and often only a small section of an individual grape’s surface is visible to the 3D camera. The difficulty is further increased by the performance and low resolution of commercially available 3D cameras. These factors combine to make traditional sphere detection algorithms ineffective at solving this problem.
A unique aspect of a sphere is that all surface normals (the direction a surface faces) can be projected through a single point, the centre of the sphere. This concept can be used to robustly detect spheres within 3D camera scans. However, as the captured point-cloud is not perfect, the normals will not intersect at a single point. To address this, a least squares approach can be used to determine the most acceptable intersection point. Once the centre point has been found, a radius can also be estimated by calculating its distance from the original captured points. To accelerate processing, a random selection of three points can be used to generate an estimate of the intersection. By repeated sampling of a point cloud in this way, a cloud of potential centre locations can be formed. Figure 1 below demonstrates the results of this approach applied to a hemispherical point cloud.
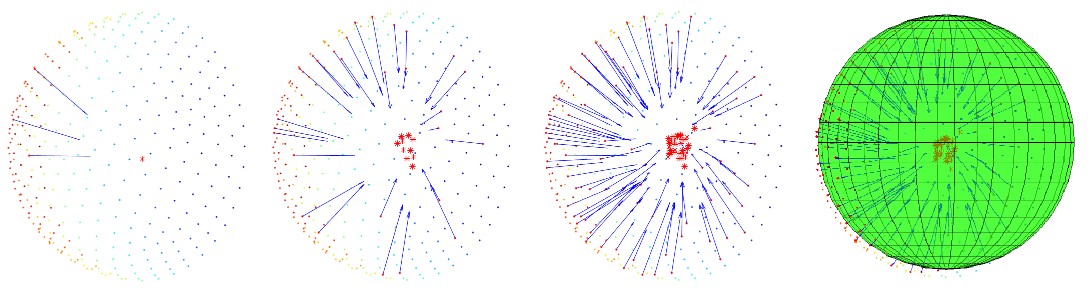
Figure 1: Result of proposed algorithm. The plots from left to right shows the progression of the algorithm at 1, 15, and 35 iterations. The resulting fitted sphere is shown in the final image. The centre is determined from the average of all proposed centre points and the radius is obtained from the average of all potential radii calculated in each iteration.
For a point-cloud representing a single spherical object, as seen in Figure 1, it is trivial to determine the average centre position and radius of the sphere. However, if the same approach is applied to a point-cloud containing multiple potential spherical objects, the result will be a point-cloud of multiple clusters, each representing the centre of a potential sphere. An example of this can be seen in Figure 2. To isolate potential spheres from this point-cloud, a clustering algorithm must be employed that is able to identify each unique cluster.
Once the cluster has been identified, it is then possible to determine a confidence estimate based on the density and distribution of the cluster. A cluster consisting of many tightly packed points is a strong indicator that a sphere exists in that location. In contrast, a coarse cluster is representative of a weak confidence. By processing all clusters in this manner, it is possible to construct a 3D reconstruction of the grape cluster with each reconstructed grape given a weighting on how much it is trusted. This metric can then be used in further stages to refine the reconstruction through growth modelling and active vision.
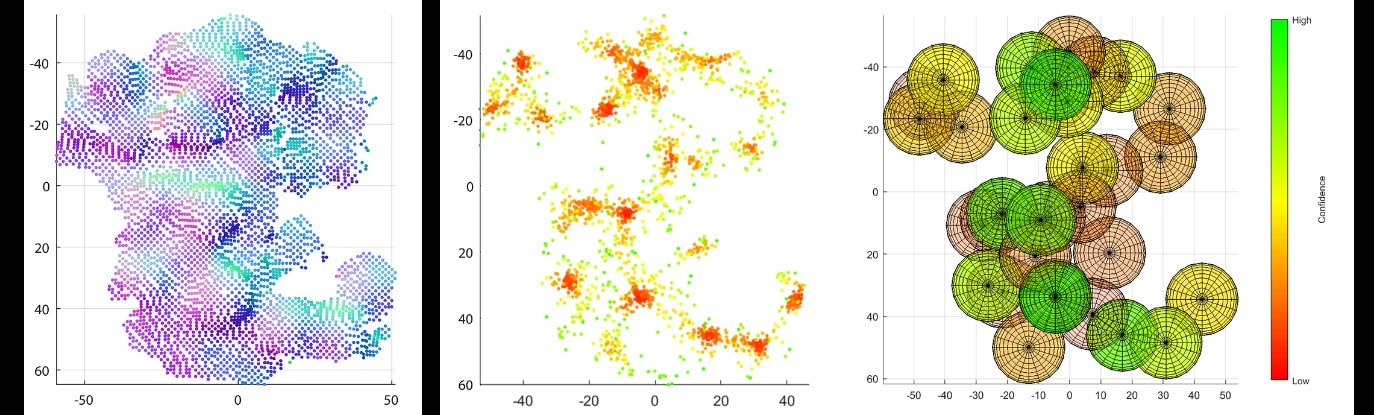
Figure 2: Steps of proposed algorithm applied to a point-cloud of a grape cluster showing the raw point-cloud (left), the point-cloud representing potential centres (middle), and the identified spheres after clustering has been performed (right). The normalised confidence of each sphere estimate is shown by their individual colour.
Algorithm Performance Between 3D Cameras
The presented algorithm can identify grape sized spherical objects in low resolution 3D camera point-clouds. However, the approach relies on 3D cameras accurately representing the curvature of the spherical surface. The degree to which individual 3D cameras achieve this varies. To analyse this, three cameras were chosen for evaluation that cover the major 3D camera technologies currently available. The cameras selected include the Microsoft Kinect V1, a structured light-based 3D camera; the Microsoft Kinect V2, a time-of-flight based 3D camera; and the recent Intel RealSense D415, an active stereo vision 3D camera.
Point-clouds were captured of a 3D printed reference bunch of grapes at a distance of 0.6 m. A computer-controlled (CNC) gantry was used to accurately position each camera. The captured clouds were then processed using the presented algorithm. The intermediary results illustrated in Figure 3 show the potential sphere centres before clustering. Clear distinctions can be made between the three results. However, most apparent is the difference in cluster distributions between the Kinect V2 and the other two cameras. The Kinect V2 has significantly smaller clusters with less spurious noise between them. This suggests that the Kinect V2 can more accurately capture the spherical curvature of the surface at this distance. This is further highlighted after the potential centres are grouped into clusters. The Kinect V2 accurately identifies all 35 visible spheres in the reference, while both the Kinect V1 and Intel D415 overestimate with 43.
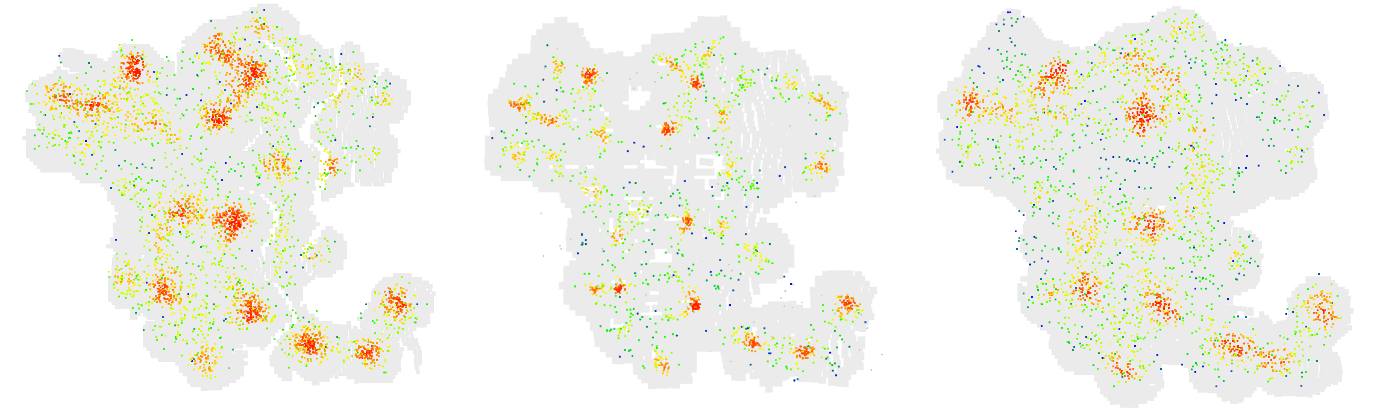
Figure 3: Comparison of clusters generated from 3D scans captured by the Kinect V1 (left), Kinect V2 (middle), Intel RealSense D415 (right).
This article first appeared in the December 2019/January 2020 issue of New Zealand Winegrower magazine












